Frequently Ask Questions
Concepts
- In my menu, I don't have all the modules that I can see on some screenshots!
- There are plenty of fields in Ishtar that I don't care of! How can I get rid of them?
- Why are data managed by archaeological operation rather than by archaeological site?
- Why use Context Records instead of Stratigraphical Units or ... ?
- Why is a Context Record necessarily linked to a parcel?
- I don't know what to use as a Context Record, what should I do?
Imports
- The first row of my CSV file is not imported, why?
- I've got problems of accents or diacritic signs not well imported!
- Is it possible to add several images in a Finds import?
- I've provided a Calc file (LibreOffice, ods format) to Ishtar for an import and that doesn't work!
Interoperability
Concepts
In my menu, I don't have all the modules that I can see on some screenshots!
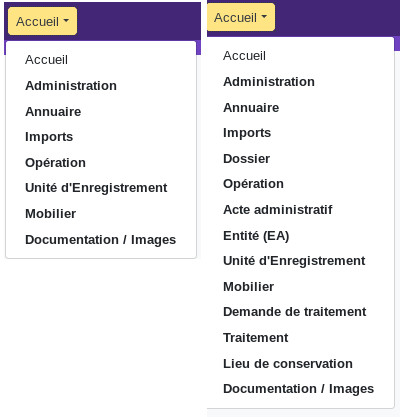
Ishtar's development is indeed modular, so that only really necessary functionalities are present in the user interface, so as not to drown the user in a profusion of functions that he never uses.
On a default instance, only modules from what is considered as the core of the software are enabled. To enable other modules, you have to be an administrator of the instance. It can be done in the administration interface, then Ishtar - common > Ishtar instance profiles, or, more directly, through the url your_instance_url/admin/ishtar_common/ishtarsiteprofile/
There are plenty of fields in Ishtar that I don't care of! How can I get rid of them?
Ishtar enables to remove any non-mandatory field from display, or to limit this perception by user type (custom forms). This can only be defined by an administrator of the database, via the administration interface. It is thus possible to adapt Ishtar to your use, first by selecting the modules which are useful to you (cartography, archaeological sites, context records, files, warehouses, etc.) then by not displaying the fields which do not seem useful to you. Note that it is possible to change your mind (modules, fields) later!
Why are data managed by archaeological operation rather than by archaeological site?
First of all, clarification on the notion of archaeological operation: it is defined as an action (or a project of action) allowing to acquire archaeological data, under the responsibility of a person (examples: incidental discovery, trial trenching, research excavation, field survey, etc.) and in a place if possible defined.
If the operation is the core of Ishtar's data model rather than the archaeological site, it is because the latter is an interpretation (like any interpretation, subject to evolution over time) of the data, whereas the operation is the information that best brings together a coherent documentary corpus linking documents (plans, reports, photos, etc.) and finds.
Within Ishtar, it is possible to create links between operations, either by associating them with the same source file (with the "administrative" module, e.g. a building permit which is associated with a trial trenching and a rescue excavation), or by defining a relationship between global operations (e.g. collective research program, motorway monitoring, etc.) and more specific operations (phases, sections, sectors, etc.). The clustering of operations is also practical in the context of research excavations, where it may be useful to have inventories for each operation per year, but also a global view of the sequence of excavations (global operation). In the context of a major rescue operation, this system can be used to identify excavation areas with specific recording methods. The user has full latitude to organize the operations between them according to his needs, as long as these key elements represent a priori coherent documentary and finds collections.
Why use Context Records instead of Stratigraphic Units or ... ?
So as not to impose a unique way of doing things on our fellow archaeologists!
Ishtar thus proposes a broad use of the concept of Context Record, defined as a volume (or surface) spatially referenced (specifically or not), associated with archaeological information and containing (or not) finds. Trench 3, structure ST25, stratigraphic unit 137 or the NE quarter of A3 square are all valid Context Records for Ishtar.
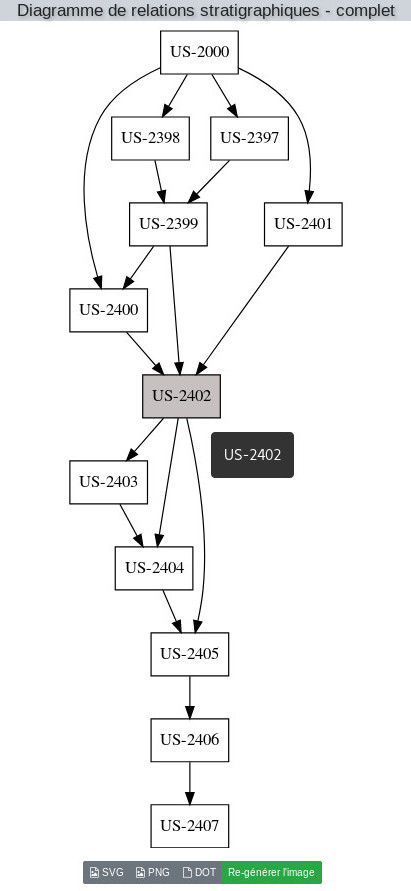
Ishtar manages relations between the Context Records. This enables in particular to define nested Context Records (for example: trench > structure > stratigraphic unit) but also to manage stratigraphic relations between stratigraphic units.
Diagrams of stratigraphic relations can be generated from each Context Record sheet. On these diagrams, inaccurate or doubtful relations (for example, a circular relation between a Context Record being both over and under another one because of a data entry error) are red-highlighted, thus enabling the user to identify and correct errors.
Ishtar's data are furthermore compatible with the use of tools such as Bruno Desachy's Stratifiant (in French only)
Why is a Context Record necessarily linked to a parcel?
For legal reasons: this enables to obtain lists of Context Records (and therefore of finds) linked to a cadastral parcel in order to define the ownership of these objects and thus facilitate the sharing or, more simply, the responsibility in the case of restoration work.
Many old inventories do not allow to define the parcel corresponding to finds: the parcel associated with the Context Record is therefore an unknown parcel.
On an instance where there is absolutely no need of parcels, it is however possible to disable this requirement in the administration interface.
I don't know what to use as a Context Record, what should I do?
You're damned! No, actually, everything is under control. One of Ishtar's principles is to allow the best possible data standardisation, in order to maximize the possibility of data reuse and statistics; but that should never be a hurdle! No Context Record = creating an unknown Context Record.
Imports
The first row of my CSV file is not imported, why?
Ishtar will not take the first row into account as it often contains column names. But you can modify that behavior by setting the Skip lines parameter to 0 (default value: 1) during a New import.
I've got problems of accents or diacritic signs not well imported!
The Encoding parameter of a New import is your friend. There are three default encoding types: utf-8, ISO-8859-15, windows-1252. If the problem persists, convert your file to utf-8 in your source software, it would be surprising that you really need another encoding (utf-8 is a worldwide standard).
Is it possible to add several images for a find in an import?
Absolutely! One image per line.
Tip: the first image mentioned in the CSV file for a find will be regarded as its main image, that means the one that appears bigger on the find sheet. If you already have imported your pictures and the first mentioned one wasn't the main image for the sheet, you just need to edit the sheet of the real main image and to check the appropriate checkbox.
I've provided a Calc file (LibreOffice, ods format) to Ishtar for an import and that doesn't work!
Ishtar currently only accepts CSV, which is the standard exchange format between spreadsheets. It's accessible in all spreadsheets as basic format in the "Save" or "Save As" functions.
Interoperability
Is it possible to connect an Ishtar database to a Geographic Information System (GIS)?
Yes! This is possible if you host your own instance or, for Iggdrasil's hosting offers, if you are on the "dedicated" offer.
Upcoming tutorial (on the forum) with QGIS.